

In collaborations with researchers at the National Energy Technology Laboratory (NETL), Cerebras showed that a single wafer-scale Cerebras CS-1 can outperform one of the fastest supercomputers in the US by more than 200 X. The problem was to solve a large, sparse, structured system of linear equations of the sort that arises in modeling physical phenomena—like fluid dynamics—using a finite-volume method on a regular three-dimensional mesh. Solving these equations is fundamental to such efforts as forecasting the weather; finding the best shape for an airplane’s wing; predicting the temperatures and the radiation levels in a nuclear power plant; modeling combustion in a coal-burning power plant; and or making pictures of the layers of sedimentary rock in places likely to contain oil and gas.
Three key factors enabled the successful speedup:
- The memory performance on the CS-1.
- The high bandwidth and low latency of the CS-1’s on-wafer communication fabric.
- A processor architecture optimized for high bandwidth computing.
We will be presenting this work at the supercomputing conference SC20 this month. A paper describing it has already been uploaded to arXiv. This work opens the door for major breakthroughs in scientific computing performance. For certain classes of supercomputing problems, wafer-scale computation overcomes current barriers to enable real-time and faster than real-time performance, and other applications that may otherwise be precluded by the failure of strong scaling in current high-performance computing systems.
HPC on the CS-1
Cerebras has built the world’s largest chip. It is 72 square inches (462 cm2) and the largest square that can be cut from a 300 mm wafer.
The chip is about 60 times the size of a large conventional chip like a CPU or GPU. It was built to provide a much-needed breakthrough in computer performance for deep learning. We have delivered CS-1 systems to customers around the world, where they are providing an otherwise impossible speed boost to leading-edge AI applications in fields ranging from drug design to astronomy, particle physics to supply chain optimization, to name just a few applications.
In addition to this, we have done something a bit surprising. We used the CS-1 to do sparse linear algebra, of the kind typically used in computational physics and other scientific applications. Working with colleagues at NETL, a Department of Energy research center in West Virginia, we took a key component of their software for modeling fluid bed combustion in power plants and implemented it on the Cerebras CS-1.
The result? Using the wafer, we were able to achieve a performance more than 200 times faster than that of NETL’s Joule 2.0 supercomputer, which is an 84,000 CPU core cluster. The Joule supercomputer is the 24th fastest supercomputer in the U.S. and 82nd fastest in the world. In this post we explain what we did and how we did it, as well as the specific aspects of the wafer that made it possible. We also discuss some possible implications of this work.
HPC Model of a Power Plant
Imagine the interior of a power plant’s combustion chamber, which is a rectangular space with some height, width, and depth. We want to know the details of temperature, chemical concentrations, and fluid (air) movement throughout the chamber, over time, as fuel burns. Now think about subdividing the space into little rectangular cells—like stacks of sugar cubes. Let’s say that we have filled the chamber with a 600 × 600 × 1500 packing of 540 million little cells. We will model the physics by keeping track of the relevant quantities, like temperature, fluid velocity, partial pressure of oxygen, etc., with one average value in each cell. This is called a finite volume method.
We use the non-linear Navier-Stokes equations that describe the motions of fluid to set up a system of linear equations that describe the fluid’s momentary dynamic. The solution to the linear equations gives updated physical quantities in each cell for use in the next time-step. In this way, the computational model simulates the operation of the power plant, starting from some known initial state, as time moves forward.
Most computation time on a supercomputer goes towards solving sets of linear equations for sets of unknowns. In the language of computational science and linear algebra, we solve Ax = b, where A is a given square matrix, b is a given vector, and x is a vector of unknown elements. In computational science, there may be billions of equations and unknowns. It should be noted that the matrix A is quite special: it is exceedingly sparse, having only a handful of nonzero elements per row or column.
Because of the sparsity and size of the matrix, iterative methods are frequently used to solve these systems. Often, the specific iterative method used is from the class of Krylov subspace methods. NETL uses one of these, called the Biconjugate Gradient Stabilized method, or BiCGSTAB.
Wafer-Scale Supercomputer
The Cerebras CS-1 is the world’s first wafer-scale computer system. It is 26 inches tall and fits in a standard data center rack. It is powered by a single Cerebras wafer (Figure 1). All processing, memory, and core-to-core communication occur on the wafer. The wafer holds almost 400,000 individual processor cores, each with its own private memory, and each with a network router. The cores form a square mesh. Each router connects to the routers of the four nearest cores in the mesh. The cores share nothing; they communicate via messages sent through the mesh.
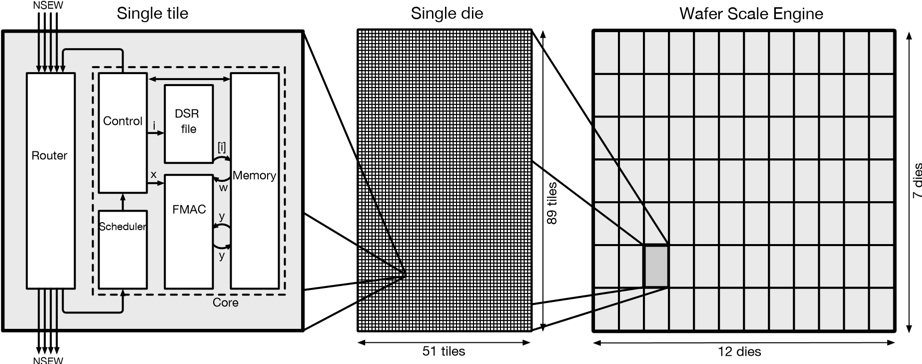
Mapping 3D Physics to the CS-1
Think of the 3D mesh of cells as a 600 × 600 mesh of stacks, where each stack is 1500 high. Each one of the 360,000 stacks is mapped to a core on the wafer. We store the data associated with the 1500 cells in each stack in the memory of its core. The four adjacent stacks of cells, that physically touch, are mapped to the four neighboring cores on the wafer (Figure 2).

Each cell requires storage for 15 matrix and vector components. Because there are 1500 cells handled by each processor core, this uses 44 kB, 90% of each core’s memory. An additional 3% of memory is used for the BiCGSTAB algorithm itself (Algorithm 1).

Performing BiCGSTAB requires three sorts of things:
- Local vector multiply-add operations (30% of FLOPS),
- Sparse matrix-vector products (50% of FLOPS),
- Dot products (20% of FLOPS).
The CS-1 has full support for IEEE 32-bit and 16-bit arithmetic. Our implementation uses 16-bit for most operations and 32-bit for the dot product’s long reduction chain. Each core plays its part, calculating its 1,500 elements for every vector computation in the loop. The CS-1 provides unique advantages for all of these operations.
Vector Multiply-Add
The vector multiply-add operations are the most memory bandwidth intensive of any part of BiCGSTAB. Each such operation reads over a billion values from memory and writes a half billion values to memory. This requires three memory accesses per scalar multiply-add operation. The CS-1 has full bandwidth to all of its memory: it can load two values and store one value for every multiply-add performed on every data-path lane, on every core, on every machine cycle.
Sparse Matrix-Vector Product
For the sparse matrix-vector operation, each core needs to gather the 6,000 values of the four neighboring stacks by communicating with its four neighboring processors. From its own stack, it forms two additional vectors by shifting the 1,500 local values up one position and down one position in order to access the cells that neighbor a given cell on the z-axis. The value shifted into the end of the vector is provided by “boundary conditions” that specify for example that the fluid flow velocity is zero along the walls of the chamber. This proceeds one element at a time, multiplying the components and accumulating a final result (Algorithm 2).

Communication between processors happens in virtual channels; these are preplanned routes, and each such channel uses one of 24 hardware supported message tags called colors. In order to send one vector and receive four from neighboring processors, the processor needs five distinct colors. This requires a clever global color assignment. We have generated a regular, periodic coloring of the mesh that assigns a different color to every processor and each of its four neighbors (Figure 3).

Memory bandwidth can also limit the speed of the sparse matrix-vector product. Since each coefficient value is used in just one multiplication, computation cannot be faster than memory bandwidth. On the CS-1 there is no slowdown because memory is as fast as it needs to be to do this at full speed.
Network bandwidth is also needed for fast sparse matrix-vector calculation. As the description above shows, whatever the distribution of cells to cores, there will be inter-core communication. With the distribution we chose (the 1×1×1500 stack per core) there is a huge amount of communication: all the stack data has to be sent to each of the four neighboring cores. The CS-1 can sustain this: the on-wafer interconnect can send out one 32-bit pair of 16-bit words to each of a given core’s four neighbors on every machine cycle and can take in one 32-bit word on the same cycle.
In contrast to the Cerebras CS-1, conventional supercomputer clusters (such as NETL’s Joule supercomputer) have orders of magnitude less communication bandwidth. Modern supercomputers require a ratio of perhaps one word communicated per 1,000 floating point operations. The same orders of magnitude difference between CS-1 and supercomputers obtains with regard to memory bandwidth. In conventional supercomputers, these limits occur at all levels: server to server, chip to chip, and because of a complex cache hierarchy within traditional processing chips, there are even communication limits for cores on the same chip. Because of these communication bottlenecks, HPC programmers on conventional systems must choose a different method of distribution.
Their solution is generally to map a smaller, though still fairly large, three-dimensional chunk of cells – say 60 × 60 × 60 – to each processor. Now only cells at the surface of the chunk, which in this case is about 6 × 60 × 60 of them, have neighboring cells on other processors with which they can communicate. This significantly limits the amount of communication taking place and lessens the bottleneck. While this is still quite a large chunk of cells, the cluster requires a coarser grained decomposition of the data, which limits the number of parallel processors that can be effectively used.
Allreduce for Dot Product
BiCGSTAB also requires dot products like <r0,ri>of global vectors. Because these vectors are identically distributed, each core performs a dot product on the vector segments (1500 elements long) that it stores, and then all processors collaborate to sum up their local results. The final summation value is broadcast back to all cores. This is known as an allreduce operation in message passing programming. It can be a big source of slowdown on a conventional parallel computer due to communication bottlenecks. It stresses the network’s communication latency rather than bandwidth. The fact that the wafer inside the CS-1 is extremely low latency is a big win.
The runtime of an efficient allreduce depends on the message latency, the time to send a short message from one processor to another. On a cluster message latency is measured in microseconds, reflecting the deep and complex, legacy communication stack used in commodity communication equipment like ethernet. On the CS-1, the single-hop communication latency is on the order of a nanosecond. How did we do that?
Communication on the wafer was designed in, not simply added on. When designing the network on the CS-1, we weren’t concerned with legacy communication needs like email or, ftp, with networked files. We use no runtime messaging software. Because we plan all routes taken through the network when a program is compiled, we can avoid congestion hotspots. Hardware stores the routing tables that can be accessed immediately when a 32-bit message presents itself at a point along its route. We employ link level flow control to make dropped messages impossible, so we do not require end-to-end acknowledgements and retry buffers. The upshot of this is that is we achieve single hop message latency in one clock cycle. As a result, we have been able to build a scalar allreduce that takes 1.3 microseconds across the entire fabric. This speed makes the dot products a minor contributor to the overall runtime of the iterative method. Because CS-1 communication latency is three orders of magnitude lower, the reduction is accomplished in a fraction of the time it would take on a cluster system.
Faster than Real-Time
The wafer scale CS-1 is the first ever system to demonstrate sufficient performance to simulate over a million fluid cells faster than real time. This means that when the CS-1 is used to simulate a power plant based on data about its present operating conditions, it can tell you what is going to happen in the future faster than the laws of physics produce that same result. (Of course, the CS-1 consumes power to do this, whereas the powerplant generates power.)
Faster than real-time model-based control is one of many exciting new applications that becomes possible with this kind of performance. Beyond a threshold, speed is not just less time to a result, but actually provides whole new operating paradigms.
To bridge the gap from a linear solver to fluid dynamics, we need to consider the full application. At the outer-most level, several iterations are performed to choose the largest stable simulation time increment. Each iteration uses the Semi-Implicit Method for Pressure Linked Equations (SIMPLE). This is the algorithm that solves Navier-Stokes by generating systems of equations at each time step. SIMPLE constructs three velocity linear systems and one pressure linear system for each phase of material (e.g., fuel and air). BiCGSTAB iterates for each linear system until it converges.
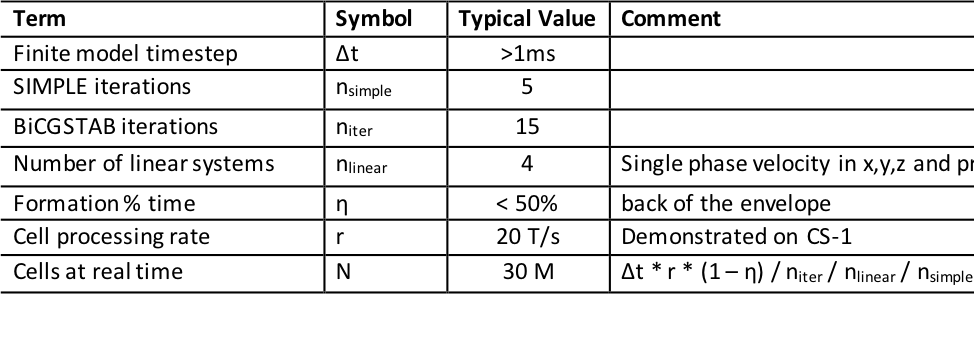
All steps used in constructing the systems of equations are also local vector operations. We make the conservative assumption that this takes 50% of total run time. Table 1 shows a first-order calculation for assessing application runtime versus number of simulated cells. A typical single-phase problem achieves real time for up to 30 M cells.
Scaling, in which Only the Strong Survive
For decades now, HPC has employed machines with ever-growing parallelism, to the point that they now have millions of cores. Making these cores all work together is the problem of scaling the application to these enormous levels of parallelism. The attempt to speed up a fixed-size problem with more processors is called strong scaling. It is generally very hard to do. It has long been understood that for a fixed problem, like our simulation on a fixed-size mesh of small cells, there was a limit to how fast the solve could be as we scaled up the number of parallel processors. Due to the portion of the computation that cannot be done in parallel there is clearly a limit, which is known as Amdahl’s Law. Everyone learns Amdahl’s Law in their first parallel computing lesson. Yet in practice, it isn’t important. In practice, it is the data movement costs that restrict the speedup achievable with a growing processor count. Consider the example above. As we strong scale, the size of the chunk of cells on a processor shrinks, meaning that the surface area of that chunk is an ever-growing fraction of the chunk’s volume. As a result, the slowdown due to limited communication bandwidth gets worse and worse. We will demonstrate that in just a bit.
What drives bigger and bigger machines, then, if strong scaling generally doesn’t work? You guessed it: weak scaling. In weak scaling, you grow the problem along with the machine. Having decided on a suitable local chunk size, you then grow the overall problem size as the machine grows in order to maintain the local chunk and the relative communication cost, and the total performance now does grow with the number of processors. Weak scaling is the dominant paradigm in HPC. It works. This is not to say that it works perfectly; it doesn’t. The allreduce runtime, for example, may get worse as you weak scale. And you will not generally reach a solution any more quickly. In fact, you may have a constant wall clock time per simulated timestep, but those timesteps may each represent a smaller amount of real time. (There is some underlying applied math that forces this to be the case.) So, you take more timesteps to simulate a time period of interest. This means that more flops are performed per second, but the time to solution is longer! So why would anyone want this? For a very good reason. The increase in the number of cells reduces the size of each of them. And the accuracy of this discrete model improves, sometimes quite dramatically, as that size is reduced. Thus, with bigger machines and weak scaling, we get better results. We just don’t get them much faster, if we get them faster at all.
Is weak scaling always enough? That depends on the intended use. There are situations in which we want to push strong scaling and get the solution times down by one or more orders of magnitude. For example, we may want to:
• Explore a large design space of parameters and solve at each possible point, in search of an optimum design;
• Explore over the space of parameters known only up to a probability density by random sampling;
• Perform a very long running simulation of phenomena that take billions of timesteps to unfold;
• Embed simulation in real-time applications to provide automatic model-based controls or assistance to human operators.
In these situations, speed trumps accuracy (although one obviously needs to start from a point of sufficient accuracy), and strong scaling is called for.
As we have shown, the communication bottlenecks of conventional parallel systems preclude much strong scaling. Here’s an illustration. Our colleagues at NETL implemented the BiCGSTAB solver for two different mesh sizes on their CPU cluster, a modern cluster of high-end Xeon servers. The plots show what happens when we strong scale with a fixed mesh size (Figure 4).
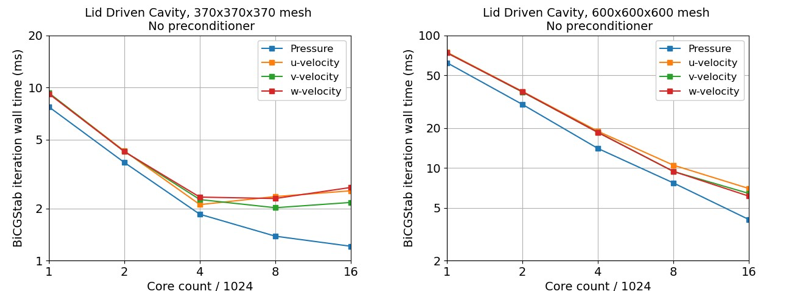
The figures give the time for one BiCGSTAB iteration, for four different linear systems. For the smaller mesh, we hit the scaling wall at 4096 cores, which is about 200 Xeon chips. The best time per iteration achieved is roughly 2 milliseconds. When we go to a bigger mesh, we are just beginning to see the slowdown at 16,384 cores on about 800 chips. And the best achievable time may be at about 5 milliseconds.
In contrast, what did the CS-1 achieve on this problem? We implemented BiCGSTAB for a 600 × 600 × 1500 mesh, roughly twice the work of the larger grid used on Joule. And the time per iteration was 28 microseconds. That is more than 200 times faster than the 800 Xeons in the Joule cluster could achieve on a finite volume mesh despite the fact the Xeons were doing much easier calculations–solving, in fact, for less than half as many cells. (In balance, Joule’s solver runs at 64-bit.)
There are two regimes in the small mesh figure. On the left, before the scaling stops, a doubling of processors produces a doubling, roughly, of performance. But is that performance good? Not compared to what the CS-1 is doing. The performance is limited by memory bandwidth. The memory bandwidth does grow as we add nodes to the cluster, but it isn’t large enough for this computation, which, as we noted above, is doing only one floating point multiply with each word of coefficient data loaded from memory. Because of the lack of data reuse, the caches that a modern processor depends on for memory access speed cannot get the job done. Then, as we strong scale, we hit the wall, because the communication times are not dropping with the growing processor count.
The Architecture of the Processor
The Cerebras CS-1 is powered by a single wafer we call the Wafer Scale Engine (WSE). The WSE contains 400,000 independent cores each with its own memory. These cores are small, powerful, and particularly efficient at accessing their own memory and communicating with neighboring cores.
Memory is the Key
On the WSE, all the memory is on the wafer. Each core has its own 48 kilobytes of memory and it is the only device that can access this memory. Nothing is shared. The memory is static random-access memory (SRAM), which is the technology used in caches. But we have no cache; only main memory. In CPUs and GPUs, performance depends on the hit ratio, the fraction of memory references that are satisfied by the L1 cache. On the wafer, every memory reference hits the local memory. The memory is small because with our high core count, computational grain size is small. Small means fast. The memory can supply 128 bits per cycle to the compute engine and store 64 bits from the compute engine on the same cycle, all at a latency of one cycle.
Having no shared memory is a major design choice. In a multicore CPU or multi-socket server, all memory is logically shared even if it is physically distributed and localized. Many nontechnical applications demand this. But shared memory doesn’t scale well for HPC or AI compute, and there are few calls for sharing between processes that have been designed to work on their own data. The benefits of no sharing are enormous. For one thing, no sharing means no cache coherence issue. The bottom line is that memory, the main performance limiting headache of conventional machines, is not a performance limiter on the wafer.
On other systems, the only things that run at near peak performance are dense matrix multiplication and other things that can be reduced to mostly matrix multiplications, as these do well in cache-based memory hierarchies. But the CS-1 does not rely on the use of matrix multiplication as the only high-performance compute kernel. Vector operations are extraordinarily high performance as well. So too are sparse matrix multiplications and many others. This widens the scope to include almost all of HPC.
Communication is the Other Key
Communication bandwidth (high) and latency (low) are critical to successful strong scaling. How do we achieve these? The answer is in the density of wiring on silicon, and the architecture we use for messages. The wiring density on the wafer is much higher than that of off-chip communication. A chip has a few thousand external pins, and most are used for power. By contrast, each chip-sized area of the wafer is connected to four similar chip-sized area by close to 10,000 on-wafer wires, all (used solely) for data.
The communication architecture on the wafer is also radically different, and radically more efficient. There is no software involved at runtime. We know at compile time what communication will be needed. So, we assign hardware buffering and routing resources to each unique communication path from a sender processor to a receiver processor. The hardware along the way is preconfigured to route this traffic. Each data packet transferred has a few bits—its “color”—that specify to every router on its route the sender-receiver pair, and the router has stored the route it should take. The flit carries a 32-bit data payload. Thus, to send data, a processor need only put the data and its color into a queue that is then read by the hardware router. After a few clocks, the data arrive at the destination processor and are deposited into a different queue that eventually plunks the data into a processor register. This is about as lean and mean as it gets. A message can traverse the link from a router to its neighbors in one machine cycle.
What happens when the packet arrives? The tag now plays a new role. When the processor finishes whatever task it is performing, a hardware function called the task picker chooses a new task. One possibility, and a high priority one, is to choose a task to handle the packet at the head of the arriving queue. And the tag of that packet is a key to a table of the code of these handlers. Therefore, the switch between tasks takes no time at all.
Communication is thus an all-hardware function. Data are transferred from registers or the memory of the sender into a register or the memory of the receiver. The overheads are minimal. This allows us to perform the allreduce operation in only slightly more time than the machine diameter, which is a lower bound on what is possible.
A New Way of Doing Scientific Computing
Because of the radical memory and communication acceleration that wafer-scale integration creates, we have been able to go far beyond what is possible in a discrete, single-chip processor, be it a CPU or a GPU.
When a problem fits on a wafer-scale machine, it will be difficult, or perhaps impossible, to match performance of the wafer-scale machine using CPUs and GPUs. This first study points the way to a breakthrough that will open the door to myriad new possibilities for scientific simulation. We look forward to continuing this work and discovering how to best exploit and realize those possibilities.
Related Posts

Cerebras CS-3 vs. Nvidia B200: 2024 AI Accelerators Compared
In the fast-paced world of AI hardware, the Cerebras CS-3 and Nvidia DGX B200…

Cerebras CS-3: the world’s fastest and most scalable AI accelerator
Today Cerebras is introducing the CS-3, our third-generation wafer-scale AI…
